Hi all,
I read the manual about sPLS with the example here sPLS Liver Toxicity Case Study – mixOmics
My understanding is that this model validates the optimal number of components through cross validated Q2.total and achieved feature selection through lassso penalization applied to the loading vectors ( maximizes the cross-validated correlation between the X- and Y-variates). And my current problem is the total Q2 is always below their suggested threshold 0.00975. Which means its predictivity is low. And I think the reason is there are too many features and only 5 samples.
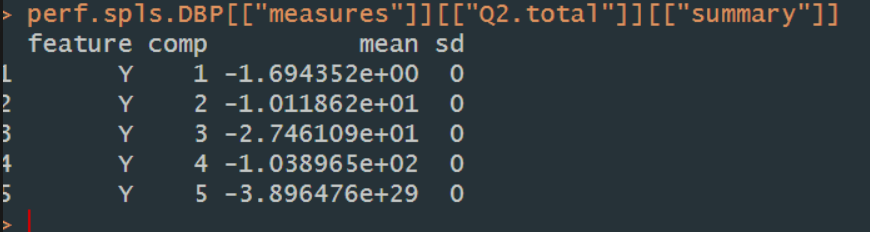
I want to ask can I still use the fitted model to visualize the association between two datasets? Can I still extracted the selected features to explain the association between two datasets? Or does it means I can not use the fitted sPLS anymore?
Best regards,
Xin