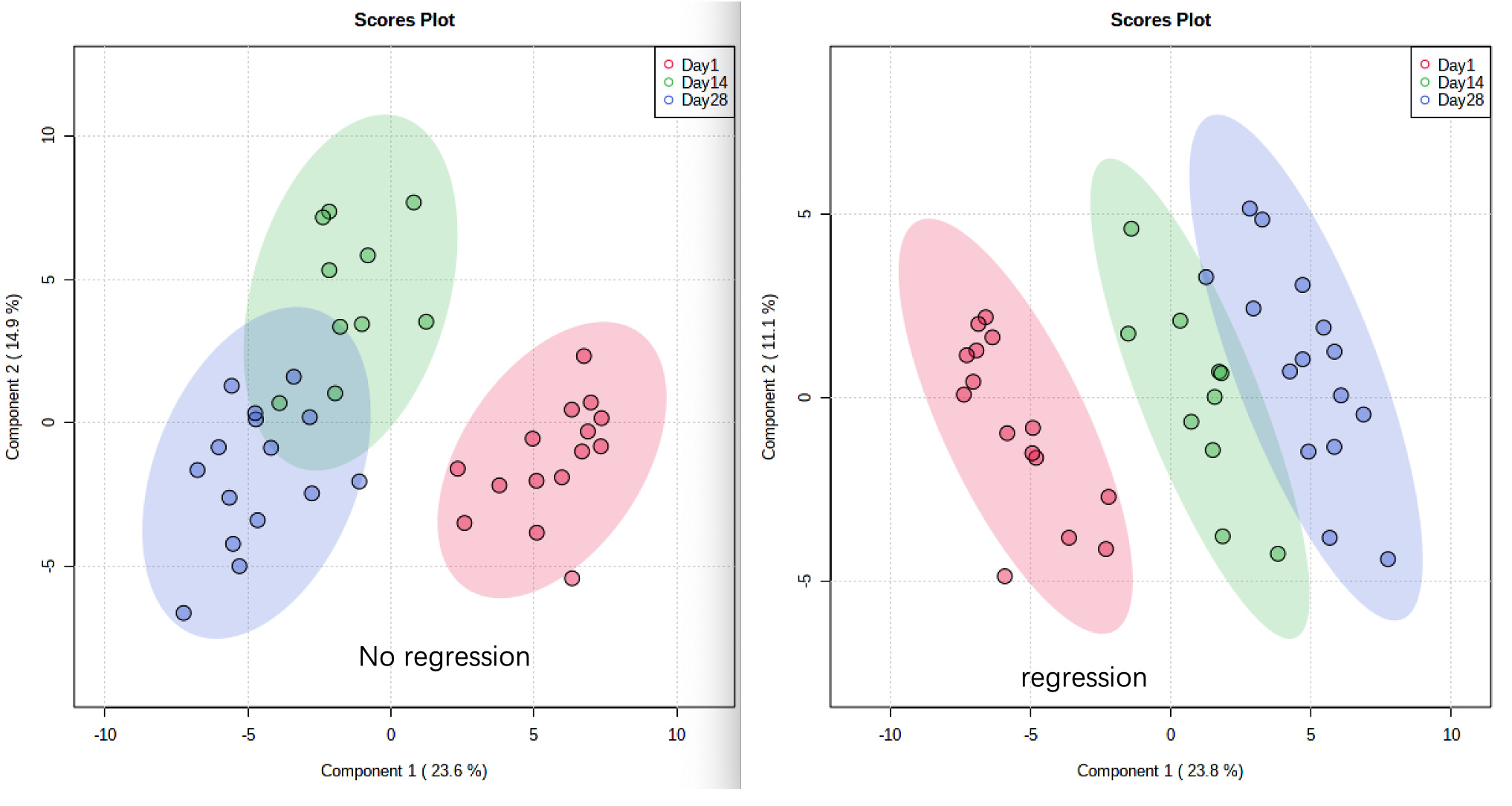
When I do plsda(). I found I got exactly same plsda score plot between chosing mode “classic” and “regression”.
I have three groups for Y matrix which is different drug dosage treatment . I thought the group order matters. So I chose regression. But I cannot perceive any difference with “classic” mode.
I tried to process same data in metaoboanalyst online below. And I can got two different plots. Is anyone know the reason?thanks a lot in advance!
The classic and regression mode refer to a slightly different way of deflating the Y data matrix in PLS-DA (e.g. calculating the residual matrix at each step of the PLS algorithm). If you only have a look at component 1, then both modes should be exactly the same since the Y matrix has not been deflated. You should be able to see a slight difference when inspecting the components after dimension 1.
The difference between both modes should appear when there are missing values (‘regression’ handles missing values in a more optimal way). We recommend in any case to use the regression mode for PLS-DA (in fact, it has become a default parameter in our latest update).
Regarding MetaboAnalyst, I am unable to comment on the implementation they propose since their code is not transparent - I have not looked at the papers either.
Thanks a lot for you explanation. Yes, i noticed that the VIPs are same no matter using “classic” or “regression” mode. However, do you think by using two different mode (class or regression), we can get different 2D score plot as I attached? Thanks!
hi @Leihan2020,
A bit of a difficult mental exercise (but you can check on the components directly), I would say comp 1 is identical and comp 2 differs. I am not sure why it would differ drastically though between both approaches if you do not have missing values.
Either way, we recommend using regression, which is our default parameter in PLSDA.