Hello,
I am very interested in using DIABLO to integrate transcriptomics and metabolomics but I am not concerned with identifying a minimal multi-omics signature and using it to classify new samples. Instead, I would like to use DIABLO to understand the main differences among my treatment groups (currently 6 different treatments and an untreated group, each having about 3 samples). Then, I just want to see the degree of correlation of these discriminating features across the omics.
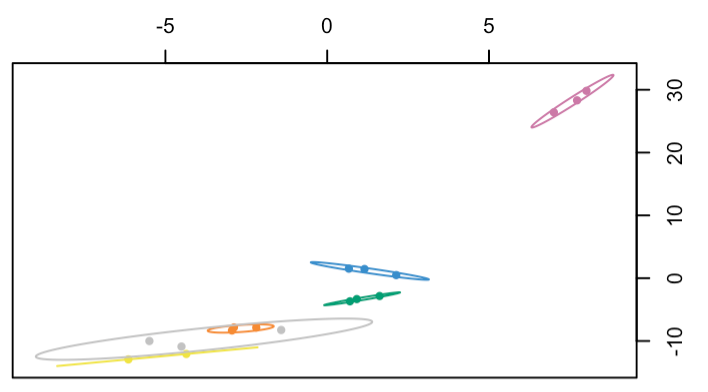
I decided to use block.splsda without specifying a keepX or doing any tuning for this exploratory approach and then visualized each component’s top loadings while paying close attention to the distinguished treatment group. For example, this plot below indicates that the pink treatment group is well distinguished on this component, so I identified its top weighted features and also analyzed these features’ correlation coefficients from the circosPlot (several of them had high R values). I thus concluded that these omics features are highly correlated and enriched in the pink treatment group (also validated by heatmaps comparing expression levels).
Screen Shot 2020-11-18 at 10.46.52 AM|690x382
{kind=link}
Is this an appropriate analysis pipeline for my purpose, and is my conclusion justified? Do you have any suggestions for me? Thank you in advance!!
-Will